
This year, Anthropic has been exceptionally vigorous.
Not only has their popularity remained high, but their reputation continues to rise, firmly establishing them as a leading player in the AI space. Almost every day, we wake up to new products or features being launched on schedule. Over time, the excitement has transformed into a tacit understanding: “It’s you again, as expected.”
Recently, the highly anticipated Claude Opus 4.7 has officially been released, maintaining the familiar formula and high performance.

Interestingly, Anthropic has been very candid in its announcement, even with a hint of pride: “This is not our most powerful model.” The legendary Claude Mythos Preview is still under wraps.
However, this not-so-powerful Opus 4.7 has still attracted significant attention because it addresses a more crucial pain point than intelligence: reliability. Not the kind of reliability where it does whatever you say, but rather the kind that challenges you when you propose a foolish idea and fills in the gaps itself.
When Reliability Becomes a Scarcer Quality Than Intelligence
Benchmark results show that on the industry’s most rigorous SWE-bench Pro, 4.7 improved from 53.4% in the previous generation to 64.3%, a nearly 11 percentage point increase, surpassing GPT-5.4 (57.7%) and Gemini 3.1 Pro (54.2%).
The visual reasoning benchmark CharXiv jumped from 69.1% to 82.1%, corresponding to its new capability of recognizing a long edge of 2576 pixels—over three times the clarity of its predecessor.
This is not just about “seeing more clearly.” The higher resolution directly drives a chain reaction of quality improvements in output: generating interfaces, creating presentations, and formatting documents, with precision in details greatly enhanced.
On the tool invocation scalability assessment MCP-Atlas, 4.7 scored 77.3%, exceeding GPT-5.4’s 68.1% and Gemini’s 73.9%. In legal AI platform Harvey’s tests, 4.7 achieved 90.9% on the BigLaw benchmark, accurately distinguishing between the historically challenging “transfer clauses” and “control change clauses.”
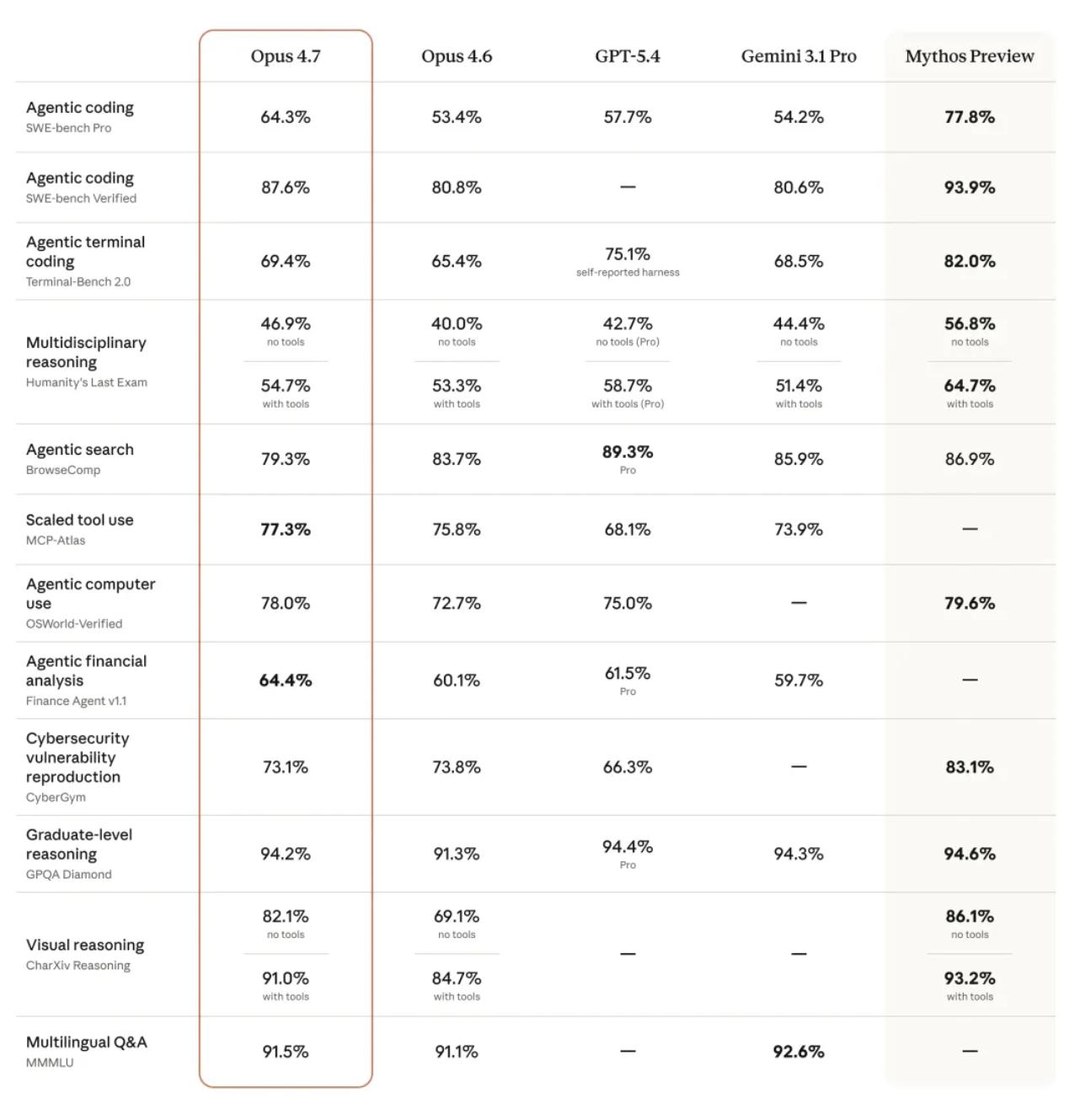
However, 4.7 is not without its shortcomings; in the Agentic search evaluation BrowseComp, it dropped from 83.7% in the previous generation to 79.3%, being surpassed by GPT-5.4 (89.3%) and Gemini (85.9%).
This decline is not coincidental. An agent that directly reports errors when faced with missing information and refuses to fabricate answers will naturally struggle in benchmarks that judge based on “whether an answer is given.”
Beyond the data, a more pressing question is: what does this kind of “reliability” truly mean in real-world work?
Over the past year, expectations for code large models have generally remained at the level of “writing a function, finding a bug,” but Claude 4.7 has demonstrated a markedly different temperament in early tests.
The head of the well-known cloud development platform Replit described it this way: “It challenges me in technical discussions, helping me make better decisions. It really feels like a better colleague.”

It no longer simply “obeys orders,” nor does it fabricate answers just to meet requirements. In tests conducted on the data science platform Hex, 4.7 directly reports errors when it encounters missing data, unlike its predecessor, which would provide a seemingly reasonable but entirely incorrect alternative value. The Hex team even stated: “In low consumption mode, 4.7 is equivalent to 4.6 in medium consumption mode.”
This “refusal to comply” characteristic is precisely what is most scarce in advanced software engineering.
Of course, there are two sides to everything. Prompts written for older models may yield unexpected results with 4.7. Those vague instructions that were previously “understood” by the model will be executed literally by 4.7. This means that the clearer you are in expressing your needs, the better results you can obtain from 4.7.
Simply being “argumentative” is not enough; an AI that shuts down when faced with setbacks is also not a good colleague. Another significant change in 4.7 is its task resilience.
In the past, large models would often stop and report errors when encountering tool invocation failures in multi-step tasks. The Notion team found that 4.7’s tool error rate has dropped to one-third of its predecessor’s, and more importantly, it can navigate around obstacles when the toolchain collapses, continuing to complete the task.
When AI stops flattering, true productivity begins to emerge.
In an extreme case disclosed by Anthropic, 4.7 built a complete Rust text-to-speech engine from scratch without any human intervention—writing neural network models, SIMD kernels, and browser demos, and even feeding the output to a speech recognizer for validation, completing the testing as well.
The front-end framework giant Vercel discovered a previously unseen behavior: 4.7 performs mathematical proofs before it starts writing system-level code. This goes beyond just writing code and enters the realm of rigorous engineering design.
The Cost of Hiring AI “Senior Experts”
To verify its attention to detail, I set up three front-end interaction scenarios, with only one evaluation criterion: whether the details are perfunctory and easily recognizable.
The first scenario involved creating a bird’s-eye view of a vinyl record player interface, with the challenge lying in the presentation of “metallic sheen” and “breathing glow.” 4.7 did not resort to cheap color gradients but realistically recreated the metallic texture through complex CSS style overlays.

The second scenario required creating an old-fashioned electric fan using only CSS, without JavaScript. Faced with this strictly limited task, some models might quietly violate the rules, but 4.7 adhered to them. It constructed the fan’s three-dimensional structure using pure CSS, with smooth transitions between low, medium, and high speeds, and the base’s perspective and shadow handling gave it a tangible feel, finding a good solution within the allowable range.

The third scenario involved creating a retro cassette player with an old tape-like noise effect. The details of the tape’s rotation were also present.
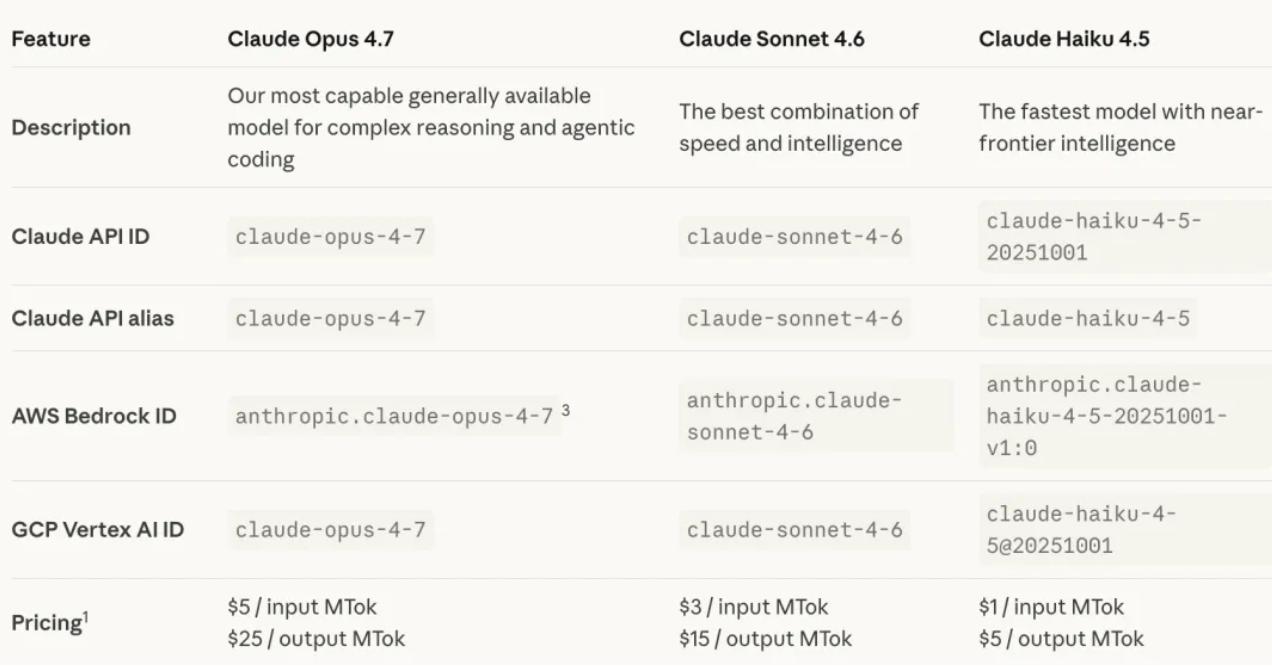
Of course, becoming smarter comes at a cost. Opus 4.7 has now been launched across all Claude products and APIs, Amazon Bedrock, Google Cloud’s Vertex AI, and Microsoft Foundry platforms.
The base pricing remains unchanged at $5 per million inputs and $25 per million outputs. However, 4.7 introduces a new tokenizer, which splits the same text into 1.0 to 1.35 times more tokens than before.
Coupled with its tendency to “think a little longer” during high-intensity tasks, actual consumption is almost certain to rise.
Additionally, Anthropic has added a new xhigh (super high) difficulty level on top of the existing options. At this level, when faced with complex problems, Claude 4.7 will consume more tokens and take more time to “think.” Claude Code has already set the default effort level for all packages to xhigh.
Anthropic is demonstrating to everyone that for genuine coding tasks, it is better to think clearly than to save on resources.
To match this workflow, Claude Code has introduced two killer features:
- /ultrareview: Initiates a dedicated review session, acting like an extremely picky senior reviewer, thoroughly reading all code changes and accurately marking deep architectural design flaws and bugs. Pro and Max users can try it for free three times.
- Auto Mode: Expanded to Max users, this new permission mode lies between “item-by-item authorization” and “skipping all permissions.” Claude will make decisions autonomously within the scope you authorize, completing lengthy and tedious tasks while being safer than complete delegation.
To prevent this “overthinking” AI from draining account balances, the API side has also launched a public beta of the “Task Budgets” feature, allowing developers to explicitly plan Claude’s token expenditure priorities in long tasks.

Of course, 4.7 is not the strongest card in Anthropic’s hand.
The more powerful Claude Mythos Preview was recently opened to a select group of enterprises for cybersecurity research under the name “Project Glasswing.” Mythos has not been publicly released because its offensive and defensive capabilities are too strong, and Anthropic feels they have not yet figured out how to safely release it to everyone.
4.7 has also made proactive trade-offs, lowering its offensive and defensive capabilities during the training phase, with built-in automatic interception mechanisms to block high-risk requests directly. Security researchers with compliance needs can apply separately through official channels.
Not rushing to play the strongest card and continuously adding new cards reflects the same underlying logic. In fact, Anthropic’s true moat lies in the rhythm of delivery itself.
From February 1 to March 24 this year, in just 52 days, Anthropic updated 74 products, averaging less than two days per update. Cowork, plugins… these actions have effectively addressed workplace pain points.
Today’s Claude ecosystem has long surpassed being merely a “chatbot.” For teams eager to deeply integrate AI into their actual workflows, this stable, high-frequency, and predictable update rhythm is the most reassuring anchor.
The newly released Claude 4.7 is the latest ballast in this chain. And that Mythos Preview will eventually come too. By then, what we currently consider to be a strong 4.7 may just be the beginning.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.